Embracing automation and robots in industry
A philosophy of automation - TM Robotics and Evershed help Ricoh automate its manufacturing process
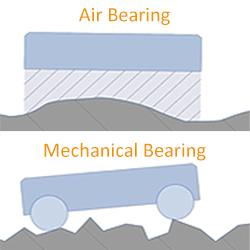
Controlling 6-Axis Hexapod Micro-Robots via EtherCAT®
Coval introduces a vacuum chamber for gripping protective masks
The Industrial Robotics Industry: Is Reemergence of the Industry on the Cards Post the COVID-19 Pandemic Settles?
Robots in the factory: bosses or slaves?
White Castle to Expand Implementations with Miso Robotics and Target Up to 10 New Locations Following Pilot
How-To Guide on Mastering PACK EXPO Connects
How Robotics Are Being Used in the Packaging Industry
How to Simplify the Integration of Robotic Automation
IMTS Connects the Manufacturing Community Through IMTS Network and IMTS spark Digital Destinations
Year-to-Date Numbers Show Decline in Robotics (18%), Machine Vision (8%), and Motion Control (6%) Orders Compared to 2019
The Lab of the Future: How New Tech Like Robotics Balances with COVID Realities
Courts Rule AI Cannot Hold Patent.
5 Ways Automation Will Change the Nature of Work
Records 151 to 165 of 849
First | Previous | Next | Last
Industrial Robotics - Featured Product