Deep Visual-Semantic Alignments for Generating Image Descriptions
Because of the Nov. 14th submission deadline for this years IEEE Conference on Computer Vision and Pattern Recognition (CVPR) several big image-recognition papers are coming out this week:
From Andrej Karpathy and Li Fei-Fei of Stanford:
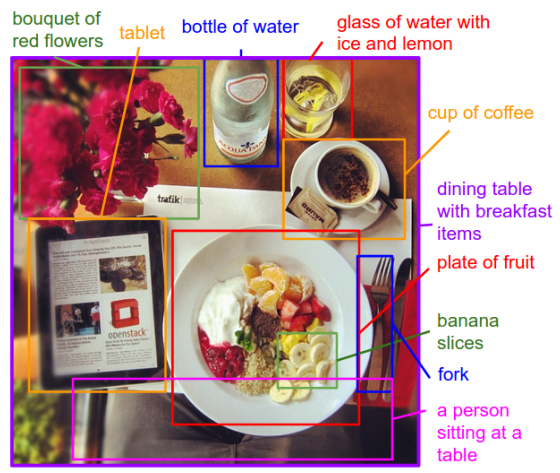
We present a model that generates free-form natural language descriptions of image regions. Our model leverages datasets of images and their sentence descriptions to learn about the inter-modal correspondences between text and visual data. Our approach is based on a novel combination of Convolutional Neural Networks over image regions, bidirectional Recurrent Neural Networks over sentences, and a structured objective that aligns the two modalities through a multimodal embedding. We then describe a Recurrent Neural Network architecture that uses the inferred alignments to learn to generate novel descriptions of image regions. We demonstrate the effectiveness of our alignment model with ranking experiments on Flickr8K, Flickr30K and COCO datasets, where we substantially improve on the state of the art. We then show that the sentences created by our generative model outperform retrieval baselines on the three aforementioned datasets and a new dataset of region-level annotations... (website with examples) (full paper)
From Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan at Google:

Show and Tell: A Neural Image Caption Generator (announcement post) (full paper)
From Ryan Kiros, Ruslan Salakhutdinov, Richard S. Zemel at University of Toronto:
Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models (full paper)
From Junhua Mao, Wei Xu, Yi Yang, Jiang Wang and Alan L. Yuille at Baidu Research/UCLA:
Explain Images with Multimodal Recurrent Neural Networks (full paper)
From Jeff Donahue, Lisa Anne Hendricks, Sergio Guadarrama, Marcus Rohrbach, Subhashini Venugopalan, Kate Saenko, and Trevor Darrell at UT Austin, UMass Lowell and UC Berkeley:
Long-term Recurrent Convolutional Networks for
Visual Recognition and Description (full paper)
All these came from this Hacker News discussion.
Comments (0)
This post does not have any comments. Be the first to leave a comment below.
Featured Product

