AI-generated images can teach robots how to act

SenseRobot's AI Chess Robot Triumphs Over Four-Time Women's World Chess Champion

AI and Cobots: The Dynamic Duo Changing Manufacturing

AI & Autonomous Solutions in Agriculture

The Warehouse of the Future: Where Sci-Fi Meets Supply Chain

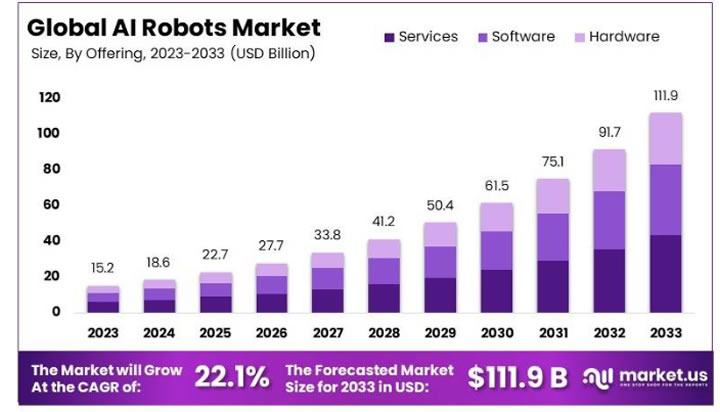
AI Robots : Transforming Industries with Smart Robotic Solutions
Future Trends of Robot Lawn Mowers in the Lawn Maintenance Industry

Figure Unveils Next-Gen Conversational Humanoid Robot With 3x AI Computing for Fully Autonomous Tasks
.jpg)
NVIDIA Accelerates Humanoid Robotics Development

The Robot Driven Logistics Industry

Skild AI Raises $300M Series A To Build A Scalable AI Foundation Model For Robotics

Adoption of Digital Twins Set to Accelerate with the Latest Release of Duality's Falcon Platform Powered by Unreal Engine

Foxconn Trains Robots, Streamlines Assembly With NVIDIA AI and Omniverse

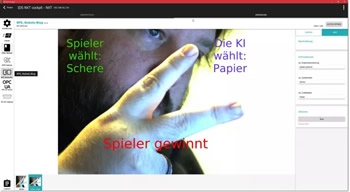
Robot plays "Rock, Paper, Scissors" - Part 2/3
How important is domain specific data? - The data challenge for AI applications in quality inspection

Records 31 to 45 of 163
First | Previous | Next | Last
Featured Product

NVIDIA RTX PRO BLACKWELL DESKTOP GPUs
Robotics and Automation - Featured Company

